본 문서에서는 2025년 PAKDD 학회에서 발표된 "DART: Diversified and Accurate Long-Tail Recommendation" 논문을 소개합니다. 논문에 대한 상세 정보는 다음과 같습니다.- Title : DART: Diversified and Accurate Long-Tail Recommendation
- Authors: Jeongin Yun, Jaeri Lee, and U Kang
- Conference: The 29th Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD 2025)
Long-tail Recommendation
비인기 아이템(tail items)을 사용자에게 추천하는 것은 재고의 균형 잡힌 관리 뿐만 아니라 사용자에게 예상치 못한 유용한 아이템을 발견하게 해주기 때문에 중요합니다. 그러나 이는 현실 세계의 구매 데이터가 long-tail 분포를 따르기 때문에 쉽지 않습니다. 구매 이력 데이터가 long-tail 분포를 따른다는 것은 아래 그림과 같이 소수의 인기 아이템(head items)이 대부분의 거래를 차지하고, 나머지 대다수의 아이템들은 매우 적은 수의 구매 이력을 가진다는 것을 의미합니다.
그림 1. 구매 이력 데이터의 long-tail 분포
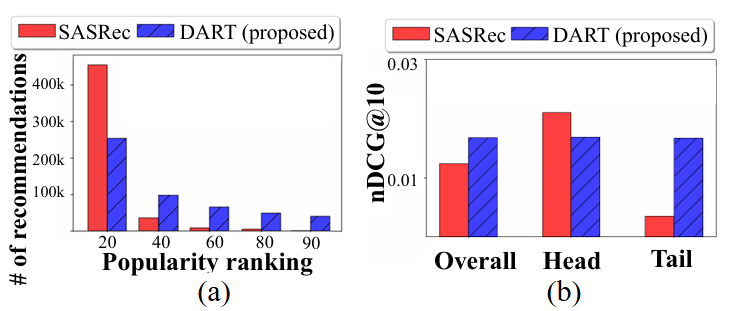
이러한 분포를 고려하지 않는 모델은 인기 아이템을 위주로 추천하고 비인기 아이템을 간과하는 문제가 발생합니다. 아래 그림 2 (a)를 보면, 대표적인 추천 모델인 SASRec은 비인기 아이템을 거의 추천하지 않고, 인기 아이템만 과도하게 추천하는 경향이 있음을 확인할 수 있습니다. 게다가, 그림 2 (b)에서 이 모델은 정답이 tail 아이템일 경우 매우 낮은 정확도를 보입니다.
그림 2. (a) 아이템 인기도에 따른 추천 빈도, (b) 전체, head, tail 아이템에 대한 추천 정확도
비인기 아이템을 추천하는 것의 어려움은 주로 다음 두 가지 이유에서 발생합니다. 첫째, 비인기 아이템은 거래 빈도가 낮아 학습 데이터 수가 부족합니다. 이로 인해 해당 아이템에 대한 embedding은 충분히 학습될 기회를 갖지 못합니다. 둘째, 추천 시스템에서 일반적으로 사용하는 random negative sampling은 비인기 아이템의 embedding 학습 과정에서 치명적인 정보 왜곡을 유발할 수 있습니다. 학습 데이터 조차 적은 비인기 아이템이 한 번이라도 잘못된 부정 아이템으로 학습 된다면, 해당 비인기 아이템의 embedding에 큰 정보 왜곡이 발생할 수 있습니다.
위 문제를 해결하기 위해 본 논문에서는 DART(Diversified and AccuRate Long-Tail Recommendation)를 제안합니다. DART는 모든 인기도 그룹에 걸쳐 아이템을 고르게 추천하면서, 각 그룹 내에서도 높은 정확도를 유지하는 정확하고 다양한 추천 기법입니다. 본 논문의 문제 정의는 다음과 같습니다.
- 주어진 정보: 타임스탬프가 포함된 사용자-아이템 상호작용 데이터
- 목표: 사용자들에게 각자 k개의 아이템을 추천
- 높은 전체 추천 정확도 달성
- 정답 아이템이 비인기 아이템일 경우의 추천의 정확도 향상
- 전체 사용자에게 비인기 아이템을 추천하는 비율을 향상
Proposed Method
본 논문에서는 long-tail 분포 문제를 해결하기 위해 DART(Diversified and AccuRate Long-Tail Recommendation) 모델을 제안합니다. 그림3은 DART의 핵심 아이디어를 구조화한 것 입니다. 구매 이력 데이터셋의 불균형한 분포를 완화하기 위해 DART는 비인기 아이템의 등장 빈도를 높이는 합성 시퀀스를 생성합니다. 이 시퀀스들은 인기 아이템과 비인기 아이템 간의 유사성 관계를 파악하여, 합성 전 원본 시퀀스의 사용자 선호 정보를 보존합니다. 또한, DART는 대조 학습을 통해 아이템 간 유사성 관계가 모델에 반영되도록 하여 비인기 아이템의 embedding 벡터를 정확하게 학습합니다. 마지막으로, 인기도 기반 negative sampling을 적용함으로써 비인기 아이템의 embedding에 잘못된 정보가 학습되지 않도록 합니다.
Preference-aware Synthetic Sequence
본 논문에서는 구매 이력 데이터셋에서 인기 아이템과 비인기 아이템 간의 불균형을 완화하기 위해, 비인기 아이템의 비율을 높이는 합성 시퀀스를 생성합니다. 이때 원본 시퀀스 내 사용자 선호 정보를 보존하기 위해, 인기 아이템과 유사한 비인기 아이템을 파악하여 일부 아이템을 교체합니다. 유사성은 아이템 클러스터링을 통해 판단하며, 각 클러스터에 인기와 비인기 아이템이 균형 있게 포함되어야 의미 있는 교체가 가능합니다. 단순 임베딩 거리 기반 클러스터링은 두 그룹을 분리된 클러스터로 나누는 문제가 있어, DART는 이를 해결하기 위해 두 단계 클러스터링을 제안합니다. 먼저 인기 아이템에 대해 k-means 클러스터링을 수행한 뒤, 비인기 아이템을 클러스터 중심점과의 거리에 따라 적절히 배분합니다. 이를 통해 각 클러스터에 아이템들이 균형 있게 분포하게 되며, 합성 시퀀스 생성 시 의미 있는 아이템 교환이 가능해집니다. 자세한 과정은 논문을 참고하시길 바랍니다.
Relationship Learning via Contrastive Learning
비인기 아이템은 구매 이력이 적어, 해당 아이템의 특성을 정확히 표현하기 위한 학습 데이터가 부족합니다. 이를 보완하기 위해 본 논문은 클러스터링을 통해 파악한 아이템 간 관계를 활용하고, 같은 클러스터 내 아이템들의 임베딩을 가깝게 만드는 대조 학습을 설계합니다. 각 사용자에 대해 두 개의 합성 시퀀스를 생성하고, 이를 positive pair로 학습합니다. 이때 위의 preference-ware synthetic sequence 아이디어를 활용하는데, 아이템 교체 비율에 따라 Strong Replacement(높은 비율)와 Weak Replacement(낮은 비율) 시퀀스를 생성합니다. 이 방식은 클러스터 내 아이템 임베딩이 서로 가까워지도록 하며, 정보가 풍부한 인기 아이템이 비인기 아이템의 부족한 정보를 보완하는 효과를 유도합니다. 자세한 방식과 손실 함수는 논문을 참고하시길 바랍니다.
Popularity-aware Negative Sampling
비인기 아이템은 학습 데이터가 부족하기 때문에, 무작위 negative sampling 과정에서 잘못된 부정 샘플로 선택될 경우 embedding이 쉽게 왜곡될 수 있습니다. 이를 방지하기 위해 DART는 아이템의 인기도에 비례하여 부정 샘플을 선택하는 인기도 기반 negative sampling 방식을 적용합니다. 즉, 인기 아이템은 negative 샘플로 자주 선택되지만, 드물게 등장하는 비인기 아이템은 negative로 선택될 확률이 현저히 낮아지도록 조정합니다. 이러한 방식은 비인기 아이템이 부정확한 정보로부터 학습되는 것을 방지하고, 보다 안정적으로 embedding을 학습할 수 있도록 돕습니다.
Experiments
본 논문은 제안한 기법의 우수성을 입증하기 위해 기존 방법들과의 비교 실험을 수행하였습니다. Amazon Books, MovieLens, Yelp 등 다양한 실세계 데이터셋을 활용하여 DART의 성능을 검증하였으며, 성능 평가는 정확도와 다양성 두 측면에서 이루어졌습니다. 정확도는 nDCG@K 및 Tail nDCG@K를 통해 측정되었으며, 이 중 Tail nDCG@K는 정답 아이템이 비인기 아이템일 경우의 추천 정확도를 평가하는 지표입니다. 다양성은 Coverage@K와 Tail Coverage@K를 사용하여 측정하였으며, Coverage@K는 전체 아이템 중 추천 리스트에 포함된 아이템의 비율을, Tail Coverage@K는 추천된 tail 아이템이 전체 tail 아이템 중 차지하는 비율을 의미합니다.
실험 결과, DART는 기존 최신 기법 대비 Tail Coverage@10에서 최대 44.7%, Tail nDCG@10에서 최대 47.5% 더 높은 성능을 나타냈으며, 전체 nDCG@10 또한 최대 **22%**까지 향상되는 결과를 보였습니다. 이는 DART가 전체 정확도와 tail 정확도를 동시에 향상시키는 것은 물론, 비인기 아이템의 추천 다양성 또한 효과적으로 증대시킴을 입증합니다. 보다 자세한 실험 결과는 논문을 참고하시기 바랍니다.
 그림 4. 성능 비교 실험
그림 4. 성능 비교 실험Conclusion
본 문서에서는 2025년 PAKDD 학회에서 발표된 "DART: Diversified and Accurate Long-Tail Recommendation" 논문을 소개하였습니다. 해당 논문에서는 long-tail 분포 문제를 해결하기 위해, 다양한 인기도 그룹에 걸쳐 아이템을 고르게 추천하면서 각 그룹 내에서도 높은 정확도를 유지하는 추천 기법인 DART를 제안합니다. 제안된 모델은 실제 다양한 추천 시스템 환경에서 유용하게 활용될 수 있습니다. 예를 들어, 전자상거래 플랫폼에서는 신상품이나 niche 상품의 노출을 확대함으로써 사용자 만족도와 판매의 다양성을 동시에 높일 수 있습니다. 또한, 스트리밍 서비스나 뉴스 추천 시스템에서는 비주류 콘텐츠의 소비를 유도하여 정보 편향을 완화하고, 추천의 포괄성을 향상시킬 수 있습니다. DART는 사용자가 평소 관심은 있지만 발견하지 못했던 아이템을 추천함으로써 우연한 발견의 즐거움(serendipity)을 제공할 수 있으며, 공급자 입장에서도 보다 균형 잡힌 재고 관리가 가능하도록 도와줍니다. 본 논문에 대한 자세한 정보는 다음 링크에서 확인할 수 있습니다: 논문 링크.