Accurate Semi-Supervised Automatic Speech Recognition via Multi-hypotheses-based Curriculum Learning
본 문서에서는 2024년 PAKDD에서 발표될 "Accurate Semi-Supervised Automatic Speech Recognition via Multi-hypotheses-based Curriculum Learning" 논문을 소개합니다. 논문에 대한 상세한 정보는 다음과 같습니다.
- Title: Accurate Semi-Supervised Automatic Speech Recognition via Multi-hypotheses-based Curriculum Learning
- Authors: Junghun Kim*, Ka Hyun Park*, and U Kang (*equal contribution)
- Conference: The Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD) 2024
Hypothesis in Automatic Speech Recognition
온라인 상에 매 순간 새로운 데이터가 업로드되어 사용할 수 있는 음성 데이터가 끊임없이 생성되고 있으며, 이에 따라 음성을 텍스트로 바꿔주는 자동 음성 인식 (Automatic Speech Recognition, ASR) 기술이 온라인 상의 방대한 음성 및 동영상 데이터를 활용하기 위한 방안으로 각광받고 있습니다. 가용 음성 데이터에 대해 사람이 직접 레이블을 생성하는 것은 비용이 많이 들고, 데이터가 추가되는 속도를 따라 잡을 수 없다는 한계가 존재합니다. 이러한 이유로 이미 레이블이 되어있는 음성 데이터를 활용해 새로운 음성 데이터에 대한 자동적인 텍스트 변환이 이루어질 수 있도록 하는 반지도학습 기반 음성 인식 기술에 대한 연구가 활발하게 진행되고 있습니다.
기존 반지도학습 기반 음성 인식 기술은 레이블이 있는, 적은 양의 음성 데이터를 이용해 초기 ASR 모델을 학습시킨 후 레이블이 없는 음성 데이터에 대한 레이블을 만들어내는 방식을 사용해왔습니다. ASR 모델은 레이블이 없는 음성 데이터가 주어지면 그에 대한 음성 인식 모델의 가설 (ASR hypothesis) 을 확률과 함께 산출하고, 가장 확률이 높은 ASR 가설 (1-best hypothesis) 을 가상 레이블 (pseudo-label) 로 선택합니다. 그리고 가상 레이블을 갖게 된 음성 데이터와 레이블을 가지고 있던 음성 데이터를 함께 활용해 ASR 모델을 다시 학습합니다.
기존 ASR 방법은 가장 확률이 높은 가설을 가상 레이블로 사용하기 때문에 모델이 만들어내는 대안 가설 (alternative hypothesis) 의 정보를 활용하지 못한다는 한계를 갖습니다. 특히, 학습 초기에 모델이 충분히 학습되지 않은 상태에서 가상 레이블을 선택하고 이를 통해 다시 학습하는 과정을 반복하게 되면 모델의 학습을 방해하는 결과로 이어질 수 있습니다.
이러한 한계점을 극복하기 위해 ASR 모델이 만들어내는 다중 가설 (multiple hypotheses) 을 학습에 활용할 수 있으나 현재까지는 반지도 학습 기반 ASR 모델들을 위한 다중 가설 기반 연구가 충분히 이루어지지 않았습니다.
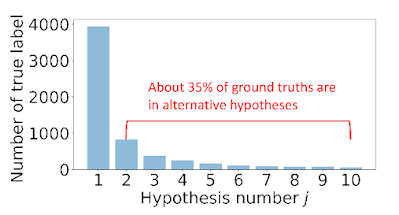 |
| 그림 1. LJSpeech 데이터셋에서 10-best 가설 중 정답 레이블이 포함된 비율 분포 |
그림 1. 은 ASR 모델이 예측한 10-best 다중 가설 중 실제로 정답이 포함된 가설의 분포입니다. 약 35%의 인스턴스들에 대해 정답 레이블은 1-best 가설로 예측되지 않았습니다. 1-best 가설을 그대로 가상 레이블로 사용하게 되면 약 35%의 인스턴스들에 대해서는 부정확한 가상 레이블을 이용해 모델을 학습하게 됩니다. 본 논문에서는 이러한 관측 결과를 바탕으로 다중 가설을 고려할 필요가 있음을 확인하고, 이를 활용해 모델의 성능을 개선시킬 수 있는 방법을 제안합니다. ASR 모델이 계산하는 1-best 가설이나 상응하는 확률에 의존하지 않고 다중 가설을 활용해 본 논문에서 해결하고자 하는 다중 가설 기반 음성 인식 모델의 문제 정의는 다음과 같습니다.
- 주어진 정보
- 레이블이 있는 적은 양의 음성 데이터
- 레이블이 없는 음성 데이터
- 기학습된 ASR 모델
- 목표
- 주어진 정보들을 활용하여 레이블이 없는 음성 인스턴스들에 대해 정확한 레이블을 생성할 수 있는 ASR 모델 학습
ASR 모델의 정보를 충분히 활용하면서 레이블이 없는 음성 인스턴스들까지 학습에 이용해 정확한 레이블을 예측할 수 있도록 하기 위해서는 다음과 같은 문제를 해결해야합니다.
- (가상 레이블의 불확실성) 기존의 1-best 가설을 가상 레이블로 사용하는 방식의 불확실성을 어떻게 개선할 수 있을까요?
- (다중 가설 활용) 레이블이 없는 인스턴스들에 대해 만들어진 다중 가설을 어떻게 학습에 활용할 수 있을까요?
- (다중 가설을 포함한 학습) 레이블이 없는 인스턴스들 간의 서로 다른 불확실성 정도를 어떻게 고려할 수 있을까요?
Proposed Method
본 논문에서는 앞서 설명한 문제점들을 해결하기 위한 기법인 Multi-hypOthesis-based Curriculum LeArning (MOCA) 를 제안합니다. 아래와 같은 핵심 아이디어들을 활용하여 MOCA 를 설계하였습니다.
- (레이블이 없는 인스턴스들에 대한 다중 가설) 레이블이 없는 인스턴스들에 대해 가장 확률이 높게 예측된 1-best 가설 대신 여러 다중 가설을 생성합니다.
- (샘플링을 통한 다중 가설 선정) ASR 모델에서 연산된 확률을 이용해 각 가설의 가중치를 정의하며 가중치가 반영된 샘플링을 통해 다중 가설을 선택하고, 그를 위한 샘플링 기반 손실 함수를 제안합니다.
- (커리큘럼 학습) 난이도가 낮은 인스턴스들부터 학습에 사용하고 점진적으로 어려운 인스턴스들을 사용합니다.

그림 2. MOCA 의 동작 과정 예시
|
| 그림 2. MOCA 의 동작 과정 예시 |
그림 2.는 MOCA의 전체적인 동작 과정을 보여줍니다. 레이블이 있는 인스턴스들을 이용해 ASR 모델을 학습하고, 학습된 모델을 이용해 레이블이 없는 인스턴스들에 대한 가설을 생성합니다. 이렇게 모든 음성 인스턴스들은 정답 레이블 또는 가상 레이블을 갖게 되고 커리큘럼 학습을 위한 인스턴스별 난이도를 연산합니다. 정해진 난이도를 기준으로 데이터를 정렬하고 쉬운 인스턴스부터 ASR 모델 학습에 사용합니다. 각 과정의 핵심적인 내용에 대해 아래에서 설명하도록 하겠습니다.
가상 레이블 선정 (Multiple Hypotheses for Unlabeled Instances)
기존 ASR 모델은 인스턴스 별로 1-best 가설을 선택해 CTC 손실 함수에 사용해왔습니다. 레이블이 있는 인스턴스들은 정답 레이블에 대해 예측된 결과가 정답으로 관측될 확률을 연산할 수 있지만, 레이블이 없는 인스턴스들은 정답 레이블이 없기 때문에 동일한 방법으로 정의할 수 없습니다. 따라서 레이블이 없는 인스턴스들에 대해 정답이 될 수 있는 가설 집합을 선정하고, 해당 집합 내에서 각 가설이 정답일 수 있는 정도를 정의하였습니다.
다중 가설을 이용한 ASR 모델 학습 (Training ASR model with Multiple Hypotheses)
앞서 정해진 값을 각 가설에 대한 가중치로 사용해 가설 집합에서 10개의 샘플을 선택합니다. 10개의 샘플을 사용함으로써 정답과 일치하는 가설이 선택될 가능성이 높아짐은 물론 비교적 불확실한 가설들까지 학습에 사용되어 더욱 강인한 모델을 만들 수 있다는 장점이 있습니다. 레이블이 있는 인스턴스와 샘플링을 통해 선택한 가상 레이블들을 새롭게 정의한 손실 함수 연산에 포함시켜 레이블이 있는 인스턴스과 레이블이 없는 인스턴스를 모두 활용할 수 있게 됩니다.
커리큘럼 학습 (Curriculum Learning)
레이블이 없는 인스턴스들에 대해 만들어진 가설 집합은 ASR 모델이 충분히 학습되지 않은 상태에서 생성되기 때문에 부정확한 경우가 많습니다. 레이블에 온전히 의존하게 되면 주어진 기학습된 ASR 모델 성능에 따라 학습 과정이 영향을 많이 받습니다. 따라서 각 음성 데이터에 대한 난이도를 정의하고 쉬운 음성 인스턴스부터 학습시키는 방식을 사용합니다. 이러한 방식을 사용하기 위해서는 음성 인스턴스와 레이블에 따른 난이도를 결정해주어야 하는데, 이를 위해 두 가지 난이도 함수를 제안합니다.
첫 번째 난이도 함수는 말하는 속도가 빠를수록 즉, 레이블의 길이에 비해 음성 인스턴스의 길이가 짧을수록 어려운 인스턴스로 판단합니다. 두 번째 난이도 함수는 말하는 속도와 더불어 모델이 연산한 불확실성이 높을수록 어려운 인스턴스로 판단합니다. 난이도 함수의 점수가 높을수록 어려운 샘플로, 낮을수록 쉬운 샘플로 정의해 학습 순서를 결정합니다.
Experiments
MOCA의 실험 결과 중 가장 중요한 두 가지 결과에 대해 설명하도록 하겠습니다.
 |
| 그림 3. MOCA 의 음성인식 성능 비교 실험 결과 |
그림 3. 의 첫 번째 실험은 1-best 가설을 사용한 알고리즘과 다중 가설을 사용한 MOCA의 성능을 비교한 실험입니다. 사용하는 다중 가설의 개수를 달리 하며 실험한 결과, 다중 가설을 활용하는 MOCA의 성능이 기존 1-best 가설을 사용하는 모델보다 항상 빠르게 수렴하고 좋은 성능을 보이는 것을 확인할 수 있습니다. 특히 10개의 다중 가설을 이용하는 모델이 5개, 3개의 다중 가설을 사용한 모델보다 일찍 수렴해 다중 가설을 이용해 모델을 학습하는 것이 학습에 도움이 된다는 것을 확인하였습니다.

표 1. MOCA ablation 결과
표 1. 의 두 번째 실험은 MOCA의 각 모듈이 모델의 성능에 얼마나 기여하고 있는지 확인하기 위한 ablation 실험입니다. 1-best 가설을 사용했을 때보다 다중 가설을 사용했을 때 성능이 개선되었습니다. 또한 다중 가설을 활용할 때 가중치를 적용해 샘플링하는 대신 모두 같은 가중치를 사용해 샘플링한 MOCA-uniform-sampling 보다 MOCA가 좋은 성능을 보입니다. 커리큘럼 학습을 적용하지 않은 모델과 커리큘럼 학습에서 정의된 인스턴스들의 순서를 역순으로 사용해 학습한 결과보다 MOCA가 높은 정확도를 보여 MOCA의 각 모듈이 학습에 필요하다는 것을 확인할 수 있습니다.
|
| 표 1. MOCA ablation 결과 |
표 1. 의
Conclusion
본 문서에서는 PAKDD에서 발표될 "Accurate Semi-Supervised Automatic Speech Recognition via Multi-hypotheses-based Curriculum Learning" 논문을 소개하였습니다. 본 논문은 음성 인식 모델의 학습에 레이블이 없는 인스턴스들까지 활용할 수 있는 다중 가설 기반 음성 인식 모델 학습 기법을 제안하였습니다. MOCA는 다중 가설을 활용해 기존 1-best 기반 음성 인식 기법보다 빠른 수렴 속도와 높은 정확도를 보입니다. 이러한 방식은 기존 기학습된 음성 인식 모델에 적용해 볼 수 있습니다. 따라서 음성 인식 기술이 사용되고 있는 실생활 음성 인식 모델들에 다방면으로 사용될 수 있으며 구체적인 예로 음성 비서, 콜 센터 상담 내용 기록이 있습니다. 특히 기존 모델의 구조를 수정하지 않고 다중 가설을 고려할 수 있어 범용적으로 사용가능한 장점이 있습니다. 논문에 대한 자세한 정보는 다음 링크에서 확인하실 수 있습니다. (링크)