본 문서에서는 PLOS ONE 저널에 게재된 "Multi-EPL: Accurate Multi-Source Domain Adaptation" 논문을 소개합니다. 논문의 상세한 정보는 다음과 같습니다.
- Title: Multi-EPL: Accurate Multi-Source Domain Adaptation
- Authors: Seongmin Lee, Hyunsik Jeon, and U Kang
- Journal: PLOS ONE (2021)
Multi-Source Domain Adaptation
MSDA (Multi-Source Domain Adaptation)는 라벨(label)이 있는 여러 소스 도메인(source domain)의 지식을 라벨이 없는 타겟 도메인(target domain)으로 적응(adaptation)하여 타겟 라벨을 정확히 예측하는 것을 목표로 합니다. 이는 다양한 국가의 환자 정보를 이용하여 한국 환자의 질병을 분류하는 문제 등을 해결하는데 이용할 수 있습니다. 기존 도메인 적응 연구들이 단일 소스 도메인의 지식을 타겟 도메인으로 전달하는 것에 집중해왔다면, 최근에는 여러 소스 도메인 지식을 동시에 이용하여 더 높은 성능을 기대할 수 있다는 점을 바탕으로 MSDA 연구들이 많이 진행되고 있습니다.
한편, 도메인 적응 기법 중 모멘트 매칭(moment matching) 기반의 방식이 가장 좋은 성능을 보이는 것으로 알려져 있습니다. 모멘트 매칭 기법은 소스 도메인 데이터와 타겟 도메인 데이터의 특징 분포(feature distribution)의 모멘트를 정렬(align)하는 접근 방식입니다. 여기서 모멘트는 분포의 평균이나 분산과 같이 분포를 수치화하는 방식 중 하나 입니다. 그러나 기존의 모멘트 매칭 기반 방식은 데이터의 라벨(label)에 따라 데이터의 분포 특징이 다를 수 있다는 점을 고려하지 않습니다. 특징 공간(feature space)상에서 데이터가 라벨에 따라 다른 곳에 위치할 수 있다는 점을 고려한다면 모멘트 매칭도 데이터의 라벨을 고려하는 것이 중요하지만 타겟 라벨을 알 수 없기 때문에 라벨에 따른 모멘트 매칭은 매우 어려운 문제입니다.
Proposed Method (Multi-EPL)
본 논문에서는 여러 소스 도메인의 지식을 이용하여 라벨이 없는 타겟 도메인의 라벨을 정확하게 예측하는 MSDA 문제를 다루기 위해 Multi-EPL (Multi-source domain adaptation with Ensemble of feature extractors, Pseudolabels, and Label-wise moment matching) 방법을 제시합니다. Multi-EPL의 전체적인 모델 구조는 그림 1과 같습니다. Multi-EPL은 두 쌍의 특징 추출기(feature extractor)와 라벨 분류기(label classifier)로 구성되어 있고, 최종 라벨 분류기로 데이터 인스턴스(instance)의 라벨을 분류합니다.
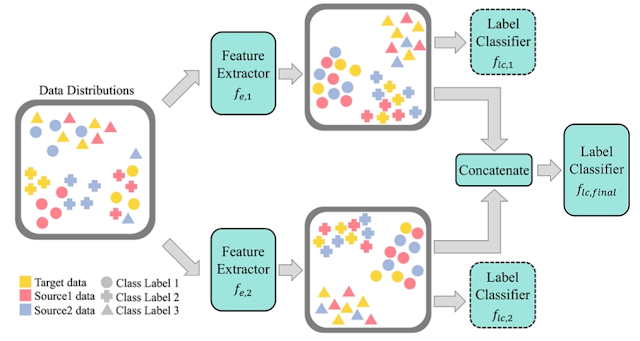
그림 1. Multi-EPL의 모델 구조
Multi-EPL의 핵심 아이디어는 1) 수도라벨을 이용한 라벨 단위의 모멘트 매칭(label-wise moment matching with pseudolabels)과 2) 특징 표현의 앙상블(ensemble of feature representations)입니다.
Multi-EPL은 모든 도메인의 데이터 인스턴스에 대해 라벨 단위로 모멘트 매칭을 합니다. 즉 특징 추출기를 통해 모든 도메인의 인스턴스를 특징 벡터(vector)로 변경한 뒤, 각 도메인의 특징 벡터들의 평균 값이 가까워지도록 학습합니다. 하지만 타겟 도메인의 데이터 인스턴스는 실제 라벨이 주어지지 않기 때문에 라벨 단위의 모멘트 매칭을 바로 적용하기 어렵습니다. 본 논문에서는 타겟 데이터 라벨은 수도라벨(pseudolabel)을 이용하는 방식으로 이 문제를 해결합니다. 수도라벨은 그림 1의 최종 라벨 분류기를 통해 예측한 값으로 부여합니다.
(2) 특징 표현의 앙상블 (ensemble of feature representations)

Multi-EPL은 그림 1과 같이 두 쌍의 특징 추출기와 라벨 분류기로 구성됩니다. 특징 추출기는 모든 도메인에 걸쳐 공유되는 모듈이기 때문에 단일 모듈로는 모든 도메인의 특징을 효과적으로 표현하기 어려울 수 있습니다. 따라서 두 쌍의 모듈로 구분하여 서로 다른 내용을 학습할 수 있도록 하여 성능을 높일 수 있습니다. 두 쌍의 모듈로 표현한 특징을 접합(concatenation)한 뒤, 최종 라벨 분류기를 통해 각 데이터 인스턴스의 라벨을 분류하게 됩니다.
Multi-EPL은 위의 두 가지 핵심 아이디어를 통해 학습되며, 라벨이 없는 타겟 데이터 인스턴스도 라벨을 예측할 수 있습니다. 더 자세한 모델 구조 설명 및 학습 방법은 논문을 참고해주시기 바랍니다.
Experiment
본 눈문은 실험을 통해 MSDA 문제에 대해 실세계 데이터셋(dataset)에서 Multi-EPL과 기존 기법들을 비교합니다. 그림 2는 Amazon Reviews 데이터셋에서 Multi-EPL과 기존 기법들의 도메인 적응 성능을 비교합니다. 도메인은 책(books), 디브이디(dvds), 전자기기(electronics), 주방기구(kitchen appliances) 네 가지로 구성되며, 하나가 타겟 도메인이고 나머지가 소스 도메인이 되도록 네 가지 실험을 진행합니다. 각 행의 최상위 열에는 타겟 도메인이 명시되어 있습니다. Multi-EPL은 모든 실험에서 기존 기법들을 앞서며 가장 정확한 도메인 적응 성능을 보입니다. 더 많은 데이터셋에 대한 성능 비교 실험은 논문을 참고해주시기 바랍니다.
그림 2. Amazon Reviews 데이터셋에서 Multi-EPL과 베이스라인(baseline)들의 도메인 적응 성능 비교
Conclusion
본 문서에서는 PLOS ONE 저널에 게재된 "Multi-EPL: Accurate Multi-Source Domain Adaptation" 논문에 대해 소개하였습니다. 해당 논문은 라벨이 있는 여러 소스 도메인의 지식을 이용하여 라벨이 없는 타겟 도메인 데이터의 라벨을 정확하게 예측하는 문제인 MSDA (Multi-Source Domain Adaptation) 문제를 해결하기 위해 Multi-EPL을 제안합니다. 실험을 통해 Multi-EPL이 기존 기법들에 비해 높은 정확도를 보이는 것을 보입니다.
MSDA 문제는 자율 주행, 의료, 제조 산업 등 다양한 분야에서 중요하게 여겨지는 문제입니다. 예를 들어, 자율 주행 연구에서는 실제 자동차가 거리를 주행하며 데이터를 충분히 수집하기 위험하고 어려운 단점이 있습니다. 따라서 가상 환경에서 많은 시간을 주행하며 데이터를 쌓아 학습하고 이 지식을 실제 환경으로 적응하는 방식으로 연구가 진행되기도 합니다. 이처럼 다른 도메인의 지식을 활용하여 문제를 해결하려는 경우에 높은 정확도를 보이는 Multi-EPL이 효과적으로 활용될 수 있을 것으로 기대됩니다. 자세한 내용은 논문에서 확인할 수 있습니다 (링크).