본 문서에서는 PLOS ONE 저널에 게재된 "Unsupervised Multi-Source Domain Adaptation with No Observable Source Data" 논문을 소개합니다. 논문의 상세한 정보는 다음과 같습니다.
- Title: Unsupervised Multi-Source Domain Adaptation with No Observable Source Data
- Authors: Hyunsik Jeon, Seongmin Lee, and U Kang
- Journal: PLOS ONE (2021)
Unsupervised Multi-Source Domain Adaptation
UMDA (Unsupervised Multi-source Domain Adaptation)는 라벨(label)이 있는 여러 소스 도메인(source domain)의 지식을 라벨이 없는 타겟 도메인(target domain)으로 적응(adaptation)하여 타겟 라벨을 정확히 예측하는 것을 목표로 합니다. 기존의 UMDA 기법들은 소스 도메인의 데이터를 모두 관측할 수 있다는 가정을 합니다. 그러나 실세계 예시에서 소스 도메인의 데이터를 관측하지 못하는 상황이 많이 있습니다. 예를 들어, 한 병원에서 질병을 예측하는 분류기를 학습할 때 다른 병원들의 충분한 데이터에서 학습한 정보를 적응하는 것을 목표로 할 수 있습니다. 하지만 환자들의 개인 정보는 개인 정보 보호의 이유로 직접 관측할 수 없기 때문에 기존 UMDA 기법들을 이용할 수 없습니다. 이처럼 기존의 UMDA 기법들은 개인 정보나 정보의 기밀성 등의 이유로 여러 실세계 상황에서 활용할 수 없습니다.
본 논문에서는 소스 데이터를 관측할 수 없는 상황에서 여러 소스 도메인의 정보를 타겟 도메인으로 적응하여 타겟 라벨을 정확히 예측하는 문제를 다룹니다. 기존의 UMDA 기법들은 모든 소스 데이터와 타겟 데이터를 관측할 수 있다는 점을 이용하여 잠재 공간(latent space) 상에서 모든 도메인의 데이터를 정렬(align)하는 접근 방식을 취합니다. 하지만 소스 데이터를 관측할 수 없는 상황에서는 모든 도메인의 데이터를 잠재 공간에 직접 정렬하는 것이 불가능합니다. 따라서 이 문제(그림 1b)는 기존 문제(그림 1a)와 다르게 모든 도메인 데이터를 잠재 공간에서 정렬하는 것이 어려운 문제입니다.
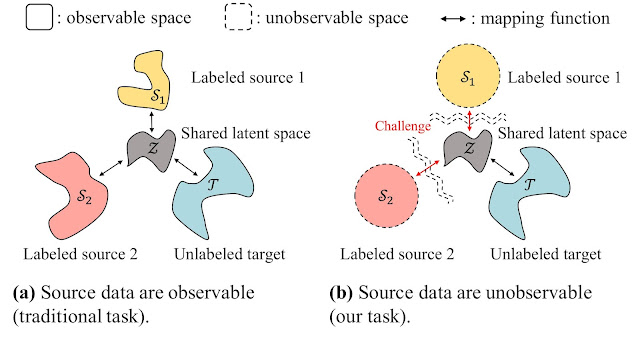
그림 1. Unsupervised multi-source domain adaptation (UMDA) 문제 비교.
본 논문에서는 소스 데이터를 볼 수 없는 상황(b)에서의 UMDA를 다룸.
Proposed Method (DEMS)
본 논문에서는 소스 데이터를 볼 수 없는 상황에서 UMDA 문제를 해결할 수 있는 방법인 DEMS (Data-free Exploitation of Multiple Sources)를 제시합니다. DEMS는 소스 데이터를 볼 수 없지만 소스 도메인에서 학습된 소스 분류기는 사용할 수 있다는 가정을 합니다. 소스 분류기를 사용하는 것은 개인 정보 보호나 기밀성 등의 이슈가 없기 때문에 실세계에서 쉽게 가정할 수 있는 상황입니다. DEMS의 핵심 아이디어는 타겟 데이터를 학습 가능한 적응 네트워트(adaptation network)로 각각의 소스 도메인으로 변환한 뒤, 주어진 소스 분류기들에 입력하여 그 결과를 통제하는 것입니다. DEMS는 다섯 가지 규제를 통해 그 결과를 통제하며, 본 문서에서는 다음 세 가지 규제에 대해 설명합니다. 나머지 두 가지 규제는 논문에서 확인할 수 있습니다.
타겟 데이터는 본래 하나의 라벨을 갖기 때문에 여러 소스 도메인으로 적응하여도 같은 라벨을 가져야 합니다. 라벨 일치 규제는 타겟 데이터가 여러 소스 도메인으로 적응되어도 분류 결과가 동일하도록 규제합니다.
(2) 엔트로피 규제 (entropy regularization)
일반적인 실세계 데이터는 대부분 라벨이 고르게 분포되어 있습니다. 엔트로피 규제는 타겟 데이터의 라벨이 고르게 분포한다는 가정을 수반합니다. 배치 엔트로피 규제는 배치 단위로 타겟 데이터를 소스 도메인으로 적응하여 소스 분류기로 분류하였을 때 나온 확률 분포들의 평균 엔트로피가 최대화되도록 합니다.
일반적인 실세계 데이터는 대부분 라벨이 고르게 분포되어 있습니다. 엔트로피 규제는 타겟 데이터의 라벨이 고르게 분포한다는 가정을 수반합니다. 배치 엔트로피 규제는 배치 단위로 타겟 데이터를 소스 도메인으로 적응하여 소스 분류기로 분류하였을 때 나온 확률 분포들의 평균 엔트로피가 최대화되도록 합니다.
(3) 가상 라벨 규제 (pseudo label regularization)
타겟 데이터를 소스 도메인으로 변환하는 것의 난이도는 각 데이터마다 다를 수 있습니다. 즉, 변환이 쉬운 데이터도 있을 수 있는 반면 어려운 데이터도 있을 수 있습니다. 변환이 쉬운 데이터는 소스 분류기를 통해 분류했을 때 확신도(confidence)가 높을 것입니다. 가상 라벨 규제는 확신도가 높은 데이터들의 라벨을 정답(ground-truth) 라벨로 설정하고 해당 라벨로 더 잘 분류되도록 규제합니다.
DEMS는 위의 규제를 통해 도메인 적응 네트워크를 먼저 학습하고, 테스트 시점에서는 타겟 데이터를 소스 도메인으로 적응한 뒤 주어진 소스 분류기들을 이용하여 타겟 라벨을 예측합니다.


타겟 데이터를 소스 도메인으로 변환하는 것의 난이도는 각 데이터마다 다를 수 있습니다. 즉, 변환이 쉬운 데이터도 있을 수 있는 반면 어려운 데이터도 있을 수 있습니다. 변환이 쉬운 데이터는 소스 분류기를 통해 분류했을 때 확신도(confidence)가 높을 것입니다. 가상 라벨 규제는 확신도가 높은 데이터들의 라벨을 정답(ground-truth) 라벨로 설정하고 해당 라벨로 더 잘 분류되도록 규제합니다.
DEMS는 위의 규제를 통해 도메인 적응 네트워크를 먼저 학습하고, 테스트 시점에서는 타겟 데이터를 소스 도메인으로 적응한 뒤 주어진 소스 분류기들을 이용하여 타겟 라벨을 예측합니다.
Experiment
본 논문은 실험을 통해 DEMS와 소스 데이터가 관측 불가능한 UMDA를 위한 다른 기법들을 비교합니다. 또한 DEMS의 적응 네트워크들이 어떻게 타겟 데이터를 소스 도메인들로 적응시키는지 질적으로 평가합니다.
그림 2는 DEMS와 비교 기법들의 성능을 다섯 가지 실세계 데이터셋(dataset)에서 비교합니다. DEMS는 모든 데이터셋에서 비교 기법들보다 우세한 성능을 보입니다. 특히, 가장 어려운 분류 데이터셋인 MNIST-M에서는 두번째 좋은 기법보다 27.5%p 높은 정확도로 큰 성능 차이를 보입니다.
그림 2. DEMS와 비교 기법들의 성능 비교.
가장 좋은 성능은 굵은 글씨체, 두번째로 좋은 성능은 밑줄로 표기함.
그림 3은 DEMS의 적응 네트워크로 MNIST-M 타겟 데이터를 다른 네 가지 소스 도메인에 적응한 결과를 보여줍니다. 처음(epoch 1)에는 적응 네트워크가 타겟 데이터를 소스 도메인으로 잘 적응하지 못합니다. 학습이 진행되면서 중간(epoch 7)에는 타겟 데이터의 의미 있는 패턴을 성공적으로 파악하고 이를 소스 도메인으로 성공적으로 적응합니다. 학습이 더 진행되면서 비교적 먼 소스 도메인(USPS)보다 비슷한 소스 도메인(MNIST, SVHN, SynDigits)으로 적응하는 것에 더 집중합니다.
그림 3. MNIST-M 타겟 데이터를 적응 네트워크로 다른 네 가지 소스 도메인에 적응한 결과.
Conclusion
본 문서에서는 PLOS ONE 저널에 게재된 "Unsupervised Multi-Source Domain Adaptation with No Observable Source Data" 논문에 대해 소개하였습니다. 해당 논문은 소스 데이터가 전혀 없는 상황에서 비지도 다중 소스 도메인 적응(unsupervised multi-source domain adaptation) 문제를 다루기 위해 DEMS를 제안합니다. 실험을 통해 DEMS가 기존 기법들에 비해 좋은 성능을 보이고, 시각화를 통해 DEMS의 적응 네트워크가 잘 학습되는 것을 보입니다. DEMS는 데이터를 쉽게 공유할 수 없는 병원, 군사 시설 등에서 분류 지식을 서로 다른 도메인으로 효과적으로 적응할 수 있도록 합니다. 더 나아가 이 연구는 데이터가 충분한 도메인의 지식을 데이터가 부족한 도메인으로 전달할 수 있는 기회를 제공하여 딥러닝의 적용 가능 분야를 더 넓힐 수 있습니다. 자세한 내용은 논문에서 확인할 수 있습니다 (링크).