본 문서에서는 NeurIPS 2019에서 발표된 Knowledge Extraction with No Observable Data 논문을 소개합니다. 논문에 대한 상세한 정보는 다음과 같습니다.
Knowledge Extraction
지식 증류(knowledge distillation)는 한 모델의 학습된 지식을 다른 모델에 전달하는 방법입니다. 예를 들면 모델 A와 B가 주어져 있는데 A는 파라미터의 수도 많고 학습 능력이 뛰어난 반면 B는 그렇지 않다고 합시다. 그러면 주어진 데이터로부터 모델 B를 직접 훈련하는 것보다 모델 A를 훈련한 다음에 A가 학습한 지식을 모델 B에 이용하는 것이 더 좋은 성능을 이끌어낼 수 있습니다.
지식 증류 알고리즘의 구체적인 동작 방식을 요약하자면 다음과 같습니다 (참고).
이러한 상황에서, 본 논문은 모델 A로부터 가짜 데이터를 생성하여 이를 지식 증류에 활용하는 새로운 딥 러닝 구조를 제안합니다. 이때 모델의 지식을 증류하기 위해서는 먼저 지식을 추출해야 한다는 의미에서, 본 논문이 해결하려는 문제를 지식 추출(knowledge extraction)이라고 합니다.
Knowledge Extraction with Generative Networks
본 논문은 KegNet(knowledge extraction with generative networks)이라는 이름의 새로운 딥 러닝 구조를 제안합니다. KegNet은 입력된 분류 모델을 기반으로 새로운 생성망(generative networks)을 학습합니다. 이 생성망은 분류 모델이 기존에 학습되었던 데이터 분포를 추론하여 그럴듯한 인공 데이터를 생성하고, 지식 증류를 가능하게 합니다. KegNet의 전체적인 구조는 다음 그림과 같습니다.
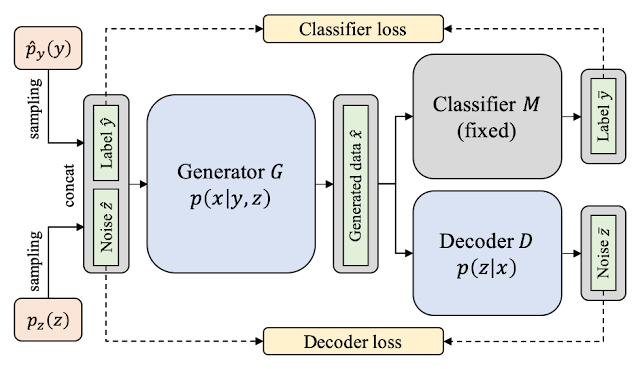
KegNet은 세 개의 인공 신경망으로 구성되어 있습니다. 첫 번째는 지식 추출의 대상인 분류 모델이며, 이 모델은 이미 잘 학습되어 입력된다고 가정합니다. 그림에서는 오른쪽 위 모델에 해당합니다. 두 번째는 임의의 라벨 벡터와 노이즈 벡터를 입력으로 받아 인공 데이터를 생성하는 생성 모델(generator)입니다. 실제로 지식 증류를 수행할 때는 이 생성 모델이 만드는 인공 데이터를 사용하며, 전체적인 KegNet 구조의 학습 목표라고 할 수 있습니다. 마지막은 디코더(decoder) 모델로 그림에서는 오른쪽 아래에 위치하고 있습니다. 각 데이터의 입력으로 주어진 저차원 임베딩 벡터를 복구하는 기능을 담당합니다.
KegNet 모델은 임의의 라벨 벡터 y가 주어졌을 때, 주어진 분류 모델이 이 y를 정확하게 예측하게 만드는 방식으로 학습됩니다. 분류 모델 자체는 고정되어 있고 학습되지 않기 때문에, 생성망 입장에서는 그림 맨 왼쪽에서 임의로 샘플링된 y를 입력으로 받아 "분류 모델이 y라고 분류할 것 같은 데이터"를 생성해야 합니다. 이러한 학습은 분류 모델이 미분 가능한 함수라고 가정했을 때, 입력된 y와 분류 모델이 출력한 y 사이에 cross-entropy 목적 함수를 최소화함으로써 간단하게 이루어집니다.
그러나, 이런 식으로 학습할 경우에는 동일한 라벨을 갖는 모든 데이터가 비슷한 모습으로 생성된다는 문제점이 있습니다. 이를 방지하기 위해, KegNet 모델에서는 노이즈 벡터 z를 라벨 벡터 y와 더불어 추가적인 입력 데이터로 사용합니다. 그런 다음, 디코더 모델이 입력된 z를 복구하게 함으로써 생성 모델이 라벨에 대한 정보 뿐 아니라 임의의 속성에 대한 정보를 데이터에 함께 추가하게 합니다. 예를 들면, 일반적으로 variational autoencoder 모델에서 예시로 들듯 데이터의 강도, 세기, 정확도 등이 이에 해당됩니다.
그림 상단과 하단에 위치한 두 개의 목적 함수를 최소화함으로써 KegNet 구조에 포함된 생성 모델과 디코더 모델이 학습됩니다. 그런 다음에는 생성 모델을 사용하여 임의의 인공 데이터를 생성할 수 있게 되고, 이 데이터를 활용하여 주어진 분류 모델의 지식을 전달할 수 있습니다. 학습이 완료된 이후에는 디코더 모델을 따로 사용하지 않습니다.
Experimental Setup
데이터가 주어지지 않은 상황에서의 지식 전파 문제는 기존에 잘 연구된 주제가 아니기 때문에, 본 논문에서는 데이터를 사용하지 않는 모델 압축(model compression)을 통해 KegNet 모델을 검증합니다. 모델 압축 문제는 딥 러닝 분야에서 가장 중요한 문제 중 하나이며 학습된 모델을 입력으로 받았을 때 이 모델의 성능을 훼손시키지 않고 모델의 크기나 연산량을 최대한 줄이는 것이 목적입니다. 대부분의 압축 알고리즘은 압축 이후에 원래 모델의 지식을 압축된 모델로 전달하는 지식 증류 과정을 거치기 때문에, 데이터가 없는 상황에서는 모델 압축이 잘 수행되기 어렵습니다.
터커 분해(Tucker decomposition) 알고리즘은 딥 러닝 모델의 웨이트 행렬 및 텐서의 크기를 줄일 수 있는 간단한 압축 알고리즘이며, 기존에 CNN이나 RNN 모델을 압축하는 데 널리 사용되어 왔습니다. 데이터가 없는 상황에서도 기본적으로 동작할 수 있지만, 압축 이후의 지식 전파 과정 없이는 정확도가 크게 떨어질 수 있습니다. 본 논문에서는 터커 분해를 기본으로 하는 다음 세 가지 알고리즘을 KegNet의 비교 대상으로 사용합니다.
Experimental Results
본 문서에서는 두 가지 종류의 실험 결과를 제시합니다. 첫 번째 결과에서는 동일한 압축 상황일 때 압축된 모델의 분류 정확도를 정량적으로 비교합니다. 그 수치가 다음 표에 자세히 나타나 있습니다. 제안한 방법인 KegNet 모델에 의해 압축되었을 때 비교 대상에 비해 훨씬 더 높은 분류 정확도를 보이는 것을 확인할 수 있습니다. 또한, 데이터의 복잡도나 압축률이 커질 때 상대적인 성능이 더 향상됩니다.

두 번째 결과에서는 SVHN 데이터셋에 대해 실제로 생성된 이미지를 살펴 보고, 인공 데이터의 질을 정성적으로 평가합니다. 아래 그림은 랜덤한 시드를 기반으로 학습된 5개의 생성 모델로부터 만들어진 인공 데이터를 표시한 것입니다. 초기의 랜덤 시드를 제외하면 각 생성 모델의 구조 및 학습 방법은 완전히 동일합니다. 주어진 라벨 벡터에 따라 각 숫자에 대응되는 인식 가능한 이미지를 생성한다는 사실과, 각 생성망에 주어진 랜덤 시드에 따라 이미지의 특성이 달라지는 것을 확인할 수 있습니다.

Conclusion
본 문서에서는 NeurIPS 2019에 발표될 예정인 "Knowledge Extraction with No Observable Data" 논문을 소개하였습니다. 해당 논문은 데이터가 없는 상황에서 지식 전파를 수행하기 위한 KegNet 구조를 제안하였고, 이 모델이 모델 압축에서 좋은 성능을 보이는 것을 실험을 통해 검증하였습니다. 실제 산업에서 딥 러닝 기술을 활용하는 경우 훈련된 모델에는 접근할 수 있지만 개인 정보 문제로 훈련에 사용된 데이터는 얻기 어려운 경우가 많습니다. 예를 들어, 공동 연구를 위해 A 병원이 B 병원으로부터 질병 탐지 모델을 공유받은 경우, 이 모델을 사용해 예측값을 만들 수는 있지만 B 병원의 원본 데이터 없이는 모델이 학습한 지식을 충분히 활용하기 어렵습니다. 본 논문에서 제시하는 KegNet 모델은 그러한 상황에서 인공 데이터를 생성함으로써 전달받은 모델의 지식을 이해하고, 이를 A 병원의 다른 모델로 전달할 수 있는 효과적인 방법을 제공합니다. 이 같은 장점은 데이터 공유가 어려운 첨단 기업, 금융 기관 등에도 동일하게 적용됩니다. 원본 논문, 코드, 포스터, 슬라이드 자료는 유재민 연구원의 홈페이지에서 찾을 수 있습니다 (링크).
- Title: Knowledge Extraction with No Observable Data
- Authors: Jaemin Yoo, Minyong Cho, Taebum Kim, and U Kang
- Conference on Neural Information Processing Systems (NeurIPS) 2019
지식 증류(knowledge distillation)는 한 모델의 학습된 지식을 다른 모델에 전달하는 방법입니다. 예를 들면 모델 A와 B가 주어져 있는데 A는 파라미터의 수도 많고 학습 능력이 뛰어난 반면 B는 그렇지 않다고 합시다. 그러면 주어진 데이터로부터 모델 B를 직접 훈련하는 것보다 모델 A를 훈련한 다음에 A가 학습한 지식을 모델 B에 이용하는 것이 더 좋은 성능을 이끌어낼 수 있습니다.
지식 증류 알고리즘의 구체적인 동작 방식을 요약하자면 다음과 같습니다 (참고).
- 훈련된 모델 A가 주어져 있다고 가정합니다.
- 데이터(피처)를 모델 A에 입력으로 주어 예측값을 저장합니다.
- 저장한 예측값을 정답으로 하여 모델 B를 학습합니다.
이러한 상황에서, 본 논문은 모델 A로부터 가짜 데이터를 생성하여 이를 지식 증류에 활용하는 새로운 딥 러닝 구조를 제안합니다. 이때 모델의 지식을 증류하기 위해서는 먼저 지식을 추출해야 한다는 의미에서, 본 논문이 해결하려는 문제를 지식 추출(knowledge extraction)이라고 합니다.
Knowledge Extraction with Generative Networks
본 논문은 KegNet(knowledge extraction with generative networks)이라는 이름의 새로운 딥 러닝 구조를 제안합니다. KegNet은 입력된 분류 모델을 기반으로 새로운 생성망(generative networks)을 학습합니다. 이 생성망은 분류 모델이 기존에 학습되었던 데이터 분포를 추론하여 그럴듯한 인공 데이터를 생성하고, 지식 증류를 가능하게 합니다. KegNet의 전체적인 구조는 다음 그림과 같습니다.

KegNet은 세 개의 인공 신경망으로 구성되어 있습니다. 첫 번째는 지식 추출의 대상인 분류 모델이며, 이 모델은 이미 잘 학습되어 입력된다고 가정합니다. 그림에서는 오른쪽 위 모델에 해당합니다. 두 번째는 임의의 라벨 벡터와 노이즈 벡터를 입력으로 받아 인공 데이터를 생성하는 생성 모델(generator)입니다. 실제로 지식 증류를 수행할 때는 이 생성 모델이 만드는 인공 데이터를 사용하며, 전체적인 KegNet 구조의 학습 목표라고 할 수 있습니다. 마지막은 디코더(decoder) 모델로 그림에서는 오른쪽 아래에 위치하고 있습니다. 각 데이터의 입력으로 주어진 저차원 임베딩 벡터를 복구하는 기능을 담당합니다.
KegNet 모델은 임의의 라벨 벡터 y가 주어졌을 때, 주어진 분류 모델이 이 y를 정확하게 예측하게 만드는 방식으로 학습됩니다. 분류 모델 자체는 고정되어 있고 학습되지 않기 때문에, 생성망 입장에서는 그림 맨 왼쪽에서 임의로 샘플링된 y를 입력으로 받아 "분류 모델이 y라고 분류할 것 같은 데이터"를 생성해야 합니다. 이러한 학습은 분류 모델이 미분 가능한 함수라고 가정했을 때, 입력된 y와 분류 모델이 출력한 y 사이에 cross-entropy 목적 함수를 최소화함으로써 간단하게 이루어집니다.
그러나, 이런 식으로 학습할 경우에는 동일한 라벨을 갖는 모든 데이터가 비슷한 모습으로 생성된다는 문제점이 있습니다. 이를 방지하기 위해, KegNet 모델에서는 노이즈 벡터 z를 라벨 벡터 y와 더불어 추가적인 입력 데이터로 사용합니다. 그런 다음, 디코더 모델이 입력된 z를 복구하게 함으로써 생성 모델이 라벨에 대한 정보 뿐 아니라 임의의 속성에 대한 정보를 데이터에 함께 추가하게 합니다. 예를 들면, 일반적으로 variational autoencoder 모델에서 예시로 들듯 데이터의 강도, 세기, 정확도 등이 이에 해당됩니다.
그림 상단과 하단에 위치한 두 개의 목적 함수를 최소화함으로써 KegNet 구조에 포함된 생성 모델과 디코더 모델이 학습됩니다. 그런 다음에는 생성 모델을 사용하여 임의의 인공 데이터를 생성할 수 있게 되고, 이 데이터를 활용하여 주어진 분류 모델의 지식을 전달할 수 있습니다. 학습이 완료된 이후에는 디코더 모델을 따로 사용하지 않습니다.
Experimental Setup
데이터가 주어지지 않은 상황에서의 지식 전파 문제는 기존에 잘 연구된 주제가 아니기 때문에, 본 논문에서는 데이터를 사용하지 않는 모델 압축(model compression)을 통해 KegNet 모델을 검증합니다. 모델 압축 문제는 딥 러닝 분야에서 가장 중요한 문제 중 하나이며 학습된 모델을 입력으로 받았을 때 이 모델의 성능을 훼손시키지 않고 모델의 크기나 연산량을 최대한 줄이는 것이 목적입니다. 대부분의 압축 알고리즘은 압축 이후에 원래 모델의 지식을 압축된 모델로 전달하는 지식 증류 과정을 거치기 때문에, 데이터가 없는 상황에서는 모델 압축이 잘 수행되기 어렵습니다.
터커 분해(Tucker decomposition) 알고리즘은 딥 러닝 모델의 웨이트 행렬 및 텐서의 크기를 줄일 수 있는 간단한 압축 알고리즘이며, 기존에 CNN이나 RNN 모델을 압축하는 데 널리 사용되어 왔습니다. 데이터가 없는 상황에서도 기본적으로 동작할 수 있지만, 압축 이후의 지식 전파 과정 없이는 정확도가 크게 떨어질 수 있습니다. 본 논문에서는 터커 분해를 기본으로 하는 다음 세 가지 알고리즘을 KegNet의 비교 대상으로 사용합니다.
- Tucker: 지식 전파 과정 없이 터커 분해만을 통해 모델을 압축합니다.
- Tucker + Uniform: 터커 분해를 통해 모델을 압축하고 균등(uniform) 분포를 따르는 임의의 데이터를 통해 지식을 전달합니다. 즉, p(x) ~ U(-1, 1)의 추정을 통해 지식을 전달합니다.
- Tucker + Normal: 터커 분해를 통해 모델을 압축하고 정규(Gaussian) 분포를 따르는 임의의 데이터를 통해 지식을 전달합니다. 즉, p(x) ~ N(0, 1)의 추정을 통해 지식을 전달합니다.
Experimental Results
본 문서에서는 두 가지 종류의 실험 결과를 제시합니다. 첫 번째 결과에서는 동일한 압축 상황일 때 압축된 모델의 분류 정확도를 정량적으로 비교합니다. 그 수치가 다음 표에 자세히 나타나 있습니다. 제안한 방법인 KegNet 모델에 의해 압축되었을 때 비교 대상에 비해 훨씬 더 높은 분류 정확도를 보이는 것을 확인할 수 있습니다. 또한, 데이터의 복잡도나 압축률이 커질 때 상대적인 성능이 더 향상됩니다.

두 번째 결과에서는 SVHN 데이터셋에 대해 실제로 생성된 이미지를 살펴 보고, 인공 데이터의 질을 정성적으로 평가합니다. 아래 그림은 랜덤한 시드를 기반으로 학습된 5개의 생성 모델로부터 만들어진 인공 데이터를 표시한 것입니다. 초기의 랜덤 시드를 제외하면 각 생성 모델의 구조 및 학습 방법은 완전히 동일합니다. 주어진 라벨 벡터에 따라 각 숫자에 대응되는 인식 가능한 이미지를 생성한다는 사실과, 각 생성망에 주어진 랜덤 시드에 따라 이미지의 특성이 달라지는 것을 확인할 수 있습니다.

Conclusion
본 문서에서는 NeurIPS 2019에 발표될 예정인 "Knowledge Extraction with No Observable Data" 논문을 소개하였습니다. 해당 논문은 데이터가 없는 상황에서 지식 전파를 수행하기 위한 KegNet 구조를 제안하였고, 이 모델이 모델 압축에서 좋은 성능을 보이는 것을 실험을 통해 검증하였습니다. 실제 산업에서 딥 러닝 기술을 활용하는 경우 훈련된 모델에는 접근할 수 있지만 개인 정보 문제로 훈련에 사용된 데이터는 얻기 어려운 경우가 많습니다. 예를 들어, 공동 연구를 위해 A 병원이 B 병원으로부터 질병 탐지 모델을 공유받은 경우, 이 모델을 사용해 예측값을 만들 수는 있지만 B 병원의 원본 데이터 없이는 모델이 학습한 지식을 충분히 활용하기 어렵습니다. 본 논문에서 제시하는 KegNet 모델은 그러한 상황에서 인공 데이터를 생성함으로써 전달받은 모델의 지식을 이해하고, 이를 A 병원의 다른 모델로 전달할 수 있는 효과적인 방법을 제공합니다. 이 같은 장점은 데이터 공유가 어려운 첨단 기업, 금융 기관 등에도 동일하게 적용됩니다. 원본 논문, 코드, 포스터, 슬라이드 자료는 유재민 연구원의 홈페이지에서 찾을 수 있습니다 (링크).